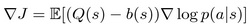深度强化学习实践

关于
作者
Maxim Lapan
译者
Google翻译
译文摘抄
Self-critical sequence training
自我批评序列训练
The described approach, despite its positive sides, has also several complications. First of all, it’s almost useless to train from scratch. Even for simple dialogs, the output sequence usually has at least five or more words, each taken from the dictionary of several thousand words. The number of different phrases of size five, with a dictionary of 1000 words equals 51000, which is slightly less than 10700. So, the probability of obtaining the correct reply in the beginning of the training (when our weights for both encoder and decoder are random) is negligibly small. To overcome this, we can combine both log-likelihood and RL approaches and pretrain our model with the log-likelihood objective first (switching between teacher forcing and curriculum learning) and after the model gets to some level of quality, switch to the REINFORCE method to fine-tune the model. In general, this could be seen as a uniform approach to complex RL problems, when a large action space makes it infeasible to start with a randomly-behaving agent, as the chance of such an agent randomly reaching the goal is negligible. There are lots of research happening around the incorporation of externally generated samples into the RL training process and using log-likelihood pretraining on correct actions is one of the approaches.
尽管 ,所描述的方法略小于 10700。因此,在训练开始时(当编码器和解码器的权重都是随机的时)获得正确答复的概率可以忽略不计。为了克服这个问题,我们可以结合对数似然和强化学习方法,首先使用对数似然目标来预训练我们的模型(在教师强制和课程学习之间切换),然后在模型达到一定质量水平后,切换到 REINFORCE 方法来微调模型。一般来说,这可以被视为解决复杂强化学习问题的统一方法,因为较大的动作空间使得从随机行为的智能体开始变得不可行,因为这种智能体随机达到目标的机会可以忽略不计。围绕将外部生成的样本纳入 RL 训练过程进行了许多研究,对正确动作使用对数似然预训练是方法之一。它有积极的一面,但也有一些并发症。首先,从头开始训练几乎没有什么用。即使对于简单的对话,输出序列通常也至少有五个或更多单词,每个单词都取自数千个单词的词典。对于 1000 个单词的字典,大小为 5 的不同短语的数量等于 5
Another issue with the vanilla REINFORCE method is the high variance of the gradients that we’ve discussed in the Chapter 10, The Actor-Critic Method. As you might remember, to solve the issue we used the Actor-Critic (A2C) method, which used the dedicated estimation of the state’s value as a variance. We can apply the A2C method that way, of course, by extending our decoder with another head and returning BLEU score estimation given the decoded sequence, but there is a better approach. In the paper a Self-Critical Sequence Training for Image Captionings [1], published by S. Rennie and E. Marcherett and others in 2016, a better baseline was proposed.
普通 REINFORCE 方法的另一个问题是我们在第 10 章“Actor-Critic 方法”中讨论过的梯度的高方差。您可能还记得,为了解决这个问题,我们使用了 Actor-Critic (A2C) 方法,该方法使用状态值的专用估计作为方差。当然,我们可以通过用另一个头扩展我们的解码器并返回给定解码序列的 BLEU 分数估计来应用 A2C 方法,但还有更好的方法。 S. Rennie 和 E. Marcherett 等人于 2016 年发表的论文《图像字幕的自我批判序列训练》[1] 中提出了更好的基线。
To obtain the baseline, the authors of the paper used the decoder in argmax mode to generate a sequence, which then was used to calculate the similarity metric like BLEU or similar. Switching to argmax mode makes the decoder process fully deterministic and provides the baseline for the REINFORCE policy gradient in the formula:
为了获得基线,论文作者使用 argmax 模式的解码器生成序列,然后使用该序列来计算 BLEU 或类似的相似性度量。切换到argmax模式使解码器过程完全确定性,并为公式中的REINFORCE策略梯度提供基线: